Randomized testing is a way for programmers to automate the discovery of interesting test cases that would be difficult or overly time consuming to come up with by hand. CockroachDB uses randomized testing in many parts of its code. I previously wrote about generating random, valid SQL. Since then we’ve added an improved SQL generator to our suite called SQLsmith, inspired by a C compiler tester called Csmith. It improves on the previous tool by generating type and column-aware SQL that usually passes semantic checking and tests the execution logic of the database. It has found over 40 new bugs in just a few months that the previous tool was unable to produce. Here I’ll discuss the evolution of our randomized SQL testing, how the new SQLsmith tool works, and some thoughts on the future of targeted randomized testing.
History of randomized testing at Cockroach Labs
The first randomized SQL testing in CockroachDB (about four years ago) came from totally normal Go fuzzing. We generated some random bytes and sent them off to our parser. Most of the time they didn’t even make it past the scanner/lexer, because most byte sequences aren’t valid SQL tokens. This approach found about 6 bugs. We don’t run this fuzzer much anymore, certainly not in our CI.
In order to make it past the lexer and actually into the parser itself, we followed up the next year with a targeted fuzzer that was SQL-aware. This works by parsing our YACC file (a file that describes how to build a parser) then randomly crawling it and generating statements from valid branches. This allowed us to produce SQL tokens in some order that the parser would accept. They often wouldn’t actually execute since the types or column or table names weren’t correct, but at least they’d parse. It could, for example, produce queries like SELECT foo FROM bar, where maybe bar wasn’t a table or if it was, foo wasn’t a column in it. This approach has found over 70 panics, race conditions, and other bugs in the three years it’s been on. It's been running nightly for a while in our CI.
Consider the path now. We started with random bytes that didn’t make it past the lexer. Then we had SQL tokens in the correct order which passed the lexer and parser, but not the semantic (type) checker. In order to cross that hurdle, we would need something that was aware of types, tables, columns, and their availability in different scopes. This is somewhat revisionist history, since at the time we didn’t realize this. But looking backward the progression is clear. Compilers have similar architectures. In the below diagram, this would be like being able to make it past all of the analyzer stages and into code generation.
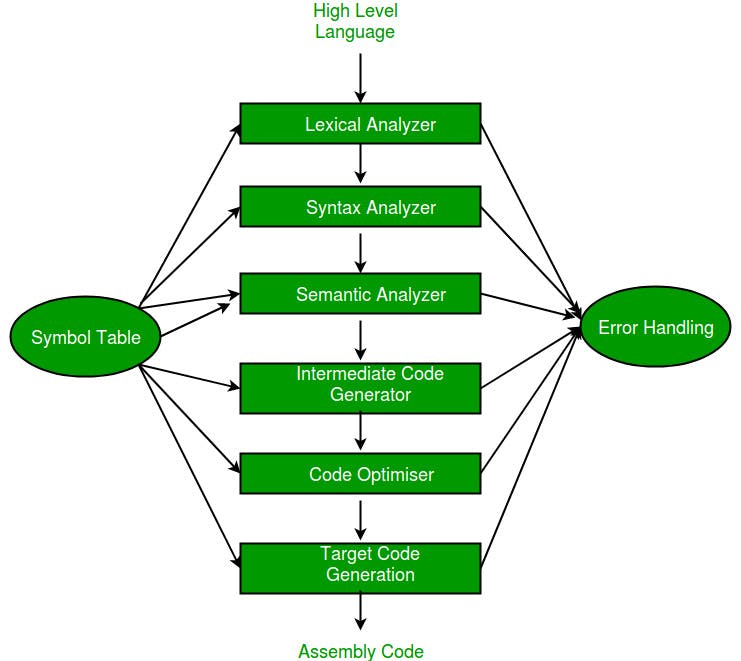
Phases of a compiler (source)
SQLsmith: a domain-aware fuzz tester
A while ago we found a program called SQLsmith, a domain-aware fuzz tester for SQL. It is written in C++ and can target Postgres while generating random queries. It begins by introspecting the database for available operators, functions, types, tables, and columns. When it generates queries it keeps track of available columns and tables and uses them. This program found over 70 bugs in Postgres.
This original SQLsmith uses a few Postgres features that CockroachDB doesn’t yet support, so it didn’t quite work out-of-the-box for us. (CockroachDB is compatible with Postgres, but sometimes we don’t fully support everything or have slightly different semantics.) We made some changes that allowed it to work with CockroachDB and it found a bunch of bugs. But since it was written in C++ and CockroachDB is written in Go, it was not immediately obvious how to integrate it into our normal testing frameworks. Another colleague ported SQLsmith from C to Go. From there it was refactored to be more integrated with CockroachDB (allowing us to test non-Postgres and other features easily). Having a Go version has lots of benefits for us: everyone here knows Go, we could hook into our existing nightly fuzz testing, and it allowed us to use our existing SQL type system and use things like randDatum which produces random constants. From there our version of SQLsmith has found over 40 panics, data races, and other bugs in CockroachDB.
This kind of fuzz testing is not able to deduce correctness. Today, its goal is limited to finding panics, which it’s quite good at. Correctness is difficult because we don’t have any oracle of truth, which would require a known working SQL engine, which is exactly the thing we’re trying to break. We are unable to use Postgres as an oracle because CockroachDB has slightly different semantics and SQL support, and generating queries that execute identically on both is tricky and doesn’t allow us to use the full CockroachDB grammar. What we can do, though, is to try to make it expert at testing various combinations of features together for which we may not have already written tests. SQL is a large language. CRUD apps exercise a tiny portion of what SQL can do. I’ve been working here for over three years and still learn new facets of SQL. These features sometimes interact in unexpected ways (well, they can cause panics). For example, the C++ SQLSmith found a bug that manifested during a set operation like UNION or INTERSECT where there was a SELECT that selected two identical constants (SELECT 1, 1). It’s impossible to hand write tests for all of the possible combinations. Hence, a domain-aware fuzzer is a useful tool to explore this space in an automated way.
How SQLsmith works
SQLsmith produces single SQL statements in a loop. The statement type (SELECT, UPDATE, INSERT, etc.) is randomly selected and its parts are randomly filled in (the FROM, LIMIT, WHERE, ORDER BY, etc.). This part is pretty simple and straightforward. Things get interesting when an expression is needed. An expression is something like a column reference, table, function, result of some unary or binary operator. Take the binary operator + that performs addition when its arguments are numbers. Each of those arguments, then, also needs to be an expression, which can continue to pick from the same list of options above, and recurse until some point.
Expression generation is where SQLsmith starts to generate interesting queries that break things. Let’s take arguments to the FROM clause of a SELECT. A FROM expects a list of table expressions. Most usually, these are just named tables (SELECT * FROM t). But lots of other things are valid table expressions also: a VALUES clause (SELECT * FROM (VALUES (1), (2));), a subquery (SELECT * FROM (SELECT * FROM t WHERE t.a = 1)), a join (SELECT * FROM a INNER JOIN b ON some_bool_expr). In CockroachDB you can use [ … ] to turn something into a table source (SELECT * FROM [DELETE FROM t RETURNING t.a]). Each of these choices allows SQLsmith to fetch from something on disk or hard code data into a query. The final example there actually performed a mutation as part of a SELECT. There are many examples of this kind of random recursion in SQLsmith.
One immediate problem that occurs in this class of testing is query runtime. SQLsmith can recursively generate queries that each have many joins, leading to a possibly huge number of result rows and a long execution time. While these kinds of queries can produce bugs, in general we want queries to be fast so we can test a higher number of them. To avoid this problem we needed a way to tell expression generators to stop recursion and instead produce some simple output. This was done by adding a complexity budget (an integer) and a function to ask if recursion can be used. The budget is decreased each request and starts returning false after it is exhausted. This method can probably be improved but it is configurable and allows us to tune how large the queries are.
Take my favorite example:
ADD COLUMN
col_40
STRING
AS (
(
SELECT
tab_44.col_18 AS col_41
FROM
defaultdb.public.t AS tab_44
CROSS JOIN defaultdb.public.t AS tab_45,
[
DELETE FROM
defaultdb.public.t AS tab_46
RETURNING
col_18 AS ret_1
]
LIMIT
1:::INT8
)
) STORED
NOT NULL;
The statement here is adding a computed column to an existing table. The value of the computed column is a subquery that does a three-way join between one on-disk table joined with itself and the result of a DELETE. The bug here is that we didn’t run the same validity checks during ALTER as we do during CREATE, so this unsupported query was allowed and then panic’d when used. SQLsmith sniffed this out because the argument to the computed column is just an expression that returns anything of type STRING. SQLsmith made a random choice to use a rather funny subquery here with a DELETE inside of it and bam, a panic. These kinds of interactions are exactly what tools like SQLsmith are good at finding.
Analysis
So far SQLsmith has found over 40 panics, data races, and other bugs in CockroachDB, in the three months since it’s been running:
- 12 missing edge case checks (a specific kind of logic error where a certain case wasn’t handled)
- 9 other kinds of logic errors
- 9 type propagation errors (like an untyped NULL)
- 2 data races
- 5 others (like incorrect text marshaling)
We have had some internal discussions trying to figure out if SQLsmith is just finding a bunch of long tail bugs that have little business value (i.e., the cost of fixing is higher than the loss of income from leaving the bug there) that would essentially be a time loss for us. Looking at the kinds of bugs it is producing, however, I do not think that these bugs are just long tail rarities that never occur in customer workloads. The original Csmith paper, whose ideas influenced the creation of the original SQLsmith, says this about the C compiler bugs they found:
"We claim that Csmith is an effective bug-finding tool in part because it generates tests that explore atypical combinations of C language features. Atypical code is not unimportant code, however; it is simply underrepresented in fixed compiler test suites. Developers who stray outside the well-tested paths that represent a compiler’s “comfort zone”—for example by writing kernel code or embedded systems code, using esoteric compiler options, or automatically generating code—can encounter bugs quite frequently. This is a significant problem for complex systems."
I believe the same is true about the usefulness of bugs that SQLsmith finds. It is nearly impossible to write tests that can come up with all possible combinations in a language as rich as SQL without a program to help automate exploring the search space.
Future Work
The most immediate future work is to run our tool against Postgres and attempt to compare the results to CockroachDB. This is difficult because, while CockroachDB and Postgres support the same wire protocol, our SQL support is only mostly the same. All the little stuff that’s not exactly the same needs to be removed from the queries. As some small examples: the type INT is 4 bytes in Postgres but 8 in CockroachDB, Postgres doesn’t have some CockroachDB-specific SQL functions, etc. Beyond language differences, one of the biggest difficulties is that output is rarely deterministic. Unless a SELECT specifies an ORDER BY, the rows can be returned in any order (and even then, rows with matching values for the ORDER BY can be returned in any order). This means a SELECT even run on the same system multiple times can return rows in a different order. This matters when there are nested SELECT statements where some of them have LIMIT clauses. If rows can legally be returned in any order then the LIMIT clause will take some random subset of them, and pass those on up to some parent SELECT, thus significantly changing the output. Producing actually deterministic output in SQL is hard, making comparison testing more tricky than expected. But these challenges can be overcome, and different results may suggest a bug present in one of the systems. Beyond that, we will continue adding features by teaching SQLsmith about new parts of SQL (views, sequences, CockroachDB-specific features like interleaved tables, etc.).
I’m also interested in applying these same ideas and principles to other parts of CockroachDB. Our Core layer is what the SQL layer uses when fetching and writing data to disk. This Core layer handles these requests while partitioning data, moving data around, handling leader elections, and other events. A domain-aware fuzzer could be taught about all of these background knobs, turn some, and then verify that the requests still function.
Conclusion
SQLsmith has added a new level of confidence when we ship new features or do refactors. It nearly always finds bugs when it is taught about more syntax or when we do large changes. We have added assertions that are often tripped by SQLsmith, helping us to find and fix bugs early on in the release cycle.
This kind of domain-aware fuzzing can be many times more useful than byte-level fuzzing. I have found that putting an hour into teaching SQLsmith about new things results in more bugs than I could find manually trying to find bugs in something. In terms of human-hours of input to number of bugs found, targeted fuzzers have been much higher than hand-written tests, and I will continue to invest time in it until it stops producing bugs.
Is building a randomized SQL fuzzer your cup of tea? Join the Cockroach Labs team!
(Also published on Matt Jibson’s blog.)